As our research project on H.T. Burleigh is beginning to come to a close, we’ve been assigned specialization tasks to divvy up the final work that has to be done in order to get the maps finished. Alongside Ian, I’ve been given the role of a data specialist, and my work is absolutely laid out in front of me. Going down row by row, cell by cell, filling in the blanks and organizing the structure of every column to match perfectly is usually a very calming and satisfying task. However, there are aspects of it that can be monotonous and oftentimes frustrating. The primary source of this at the moment is that new research hasn’t entirely ceased yet, which means every time I open a spreadsheet to commence my data cleaning, there are always a number of rows of fresh data that needs to be scoured for lat-long coordinates and proper citation. It feels at times like I’m shoveling snow during a blizzard: it’s frustrating and not the most efficient method, but it still is beneficial in the end.
Another source of frustration is the severe lack of consistency in almost every column of our spreadsheets and the lack of data completion that can be easily fulfilled by the same source that the recorded data was found. Of course, it’s literally my job as a data specialist to solve these discrepancies and fill in the blanks on the spreadsheets, but I feel like a lot of this could have been solved with a more structured and comprehensive approach to data collection from the start. If I could offer any advice for future music research both to myself and others, it would be to have a communal understanding and template for how exactly data will be entered into each column, along with an understanding that a thorough and complete scan of at least the original source of the data should be given before moving on to another entry so as to not leave unnecessary blanks in spreadsheet cells.
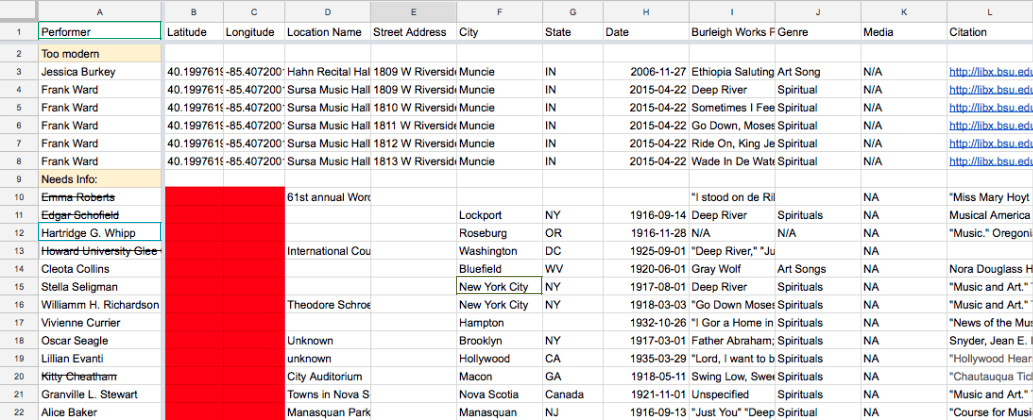
Unclean data sheet with missing information.
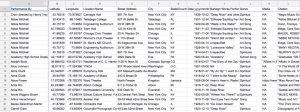
Clean data sheet with all cells filled and unified formatting.
I understand the difficulty in collecting all the data that might be called for by the column headers, and I myself am guilty of lazy citations and leaving out addresses that are easily accessible. I’ve had to go back and correct my own errors as a data specialist, and it absolutely is a learning experience. This blog post is as much for me as it is for any potential data specialists, but hopefully I’ve made my message clear that data consistency is something that should be strongly embraced and prioritized at the beginning of every research project, regardless of personal role or specialization.
You must be logged in to post a comment.